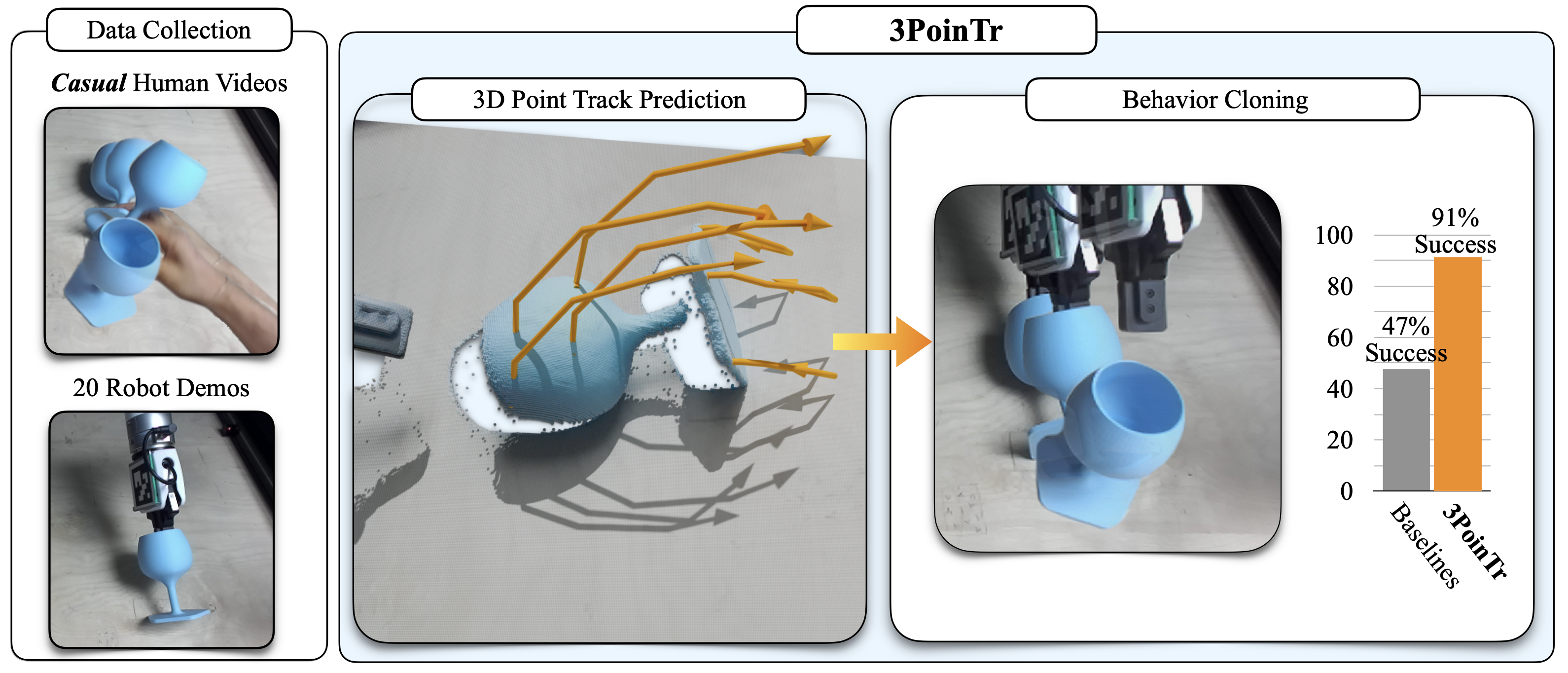
3PoinTr learns manipulation from unconstrained human videos: videos where the human demonstrator can act freely rather than mimicking target robot kinematics. 3PoinTr first predicts dense 3D point tracks — how the scene should move to complete the task — and then conditions a closed-loop multitask policy on these tracks. 3PoinTr outperforms strong behavior cloning and learning-from-video baselines across simulated and real-world evaluations.
Unconstrained Human Video Pretraining

Downstream Policy Rollouts
Abstract
Model Architecture
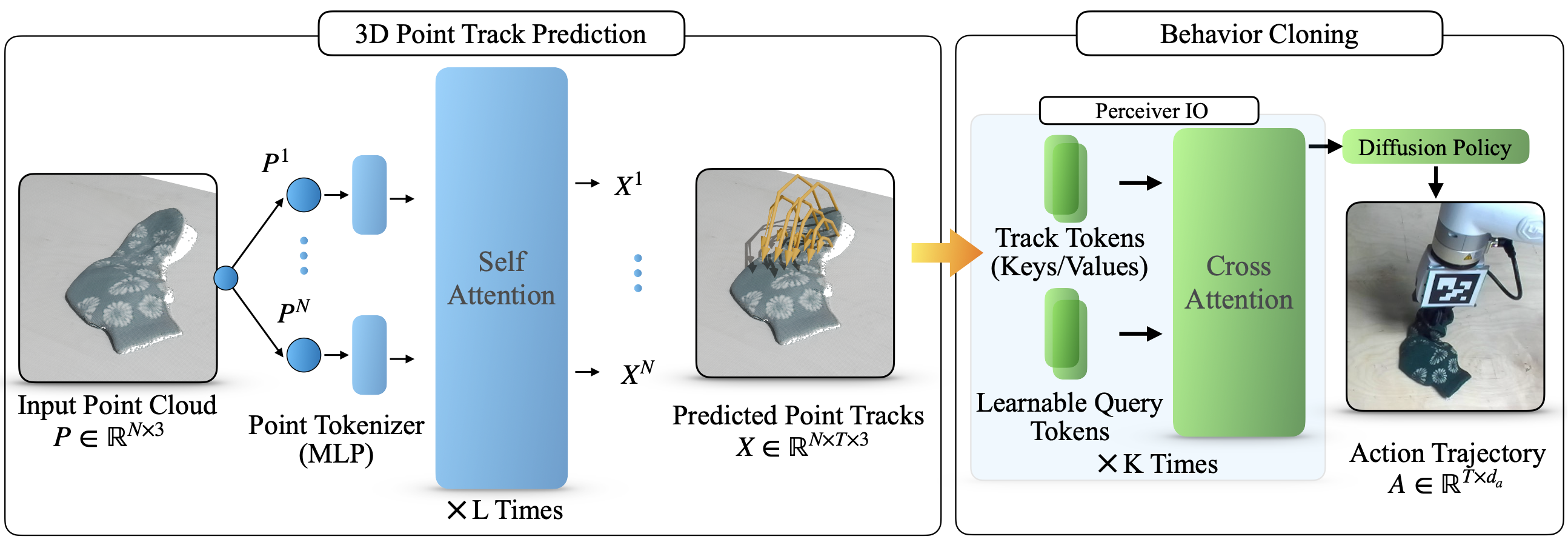
Diagram of the 3PoinTr network architecture. Given an initial point cloud, a transformer predicts dense 3D point tracks describing how objects should evolve during the task. A Perceiver-IO point track encoder compresses these tracks into a small set of learned point track tokens. The policy conditions on these point track tokens together with the current point cloud and robot state, enabling closed-loop action prediction. Beyond global conditioning, residual track-token cross-attention in every U-Net block gives the action head a direct path to the predicted object motion, encouraging a simpler mapping from point tracks to robot actions.
Results: Sample-Efficient Policy Learning
Simulation Tasks
Simulation success rates (%) evaluated over 200 rollouts per task. Results are reported for policies trained with 20, 50, and 100 action-labeled demonstrations and 100 actionless videos per task. 3PoinTr achieves the highest average success rate across all numbers of demonstrations.
Real-World Tasks
| Task | ATM | DP3 | 3PoinTr |
|---|---|---|---|
| Open Drawer | 6/20 | 14/20 | 20/20 |
| Right Glass | 3/20 | 18/20 | 20/20 |
| Throw Away Paper | 0/20 | 9/20 | 18/20 |
| Fold Sock | 7/20 | 14/20 | 17/20 |
Real-world success rates for policies trained with 20 robot demonstrations and 50 human videos per task, evaluated over 20 rollouts. 3PoinTr achieves the highest success rate on all four tasks, with a 25.0 percentage point higher average success rate than the best baseline, DP3.
Ablations
Ablation success rates (%) evaluated over 200 rollouts per simulation task, for policies trained with 20 demonstrations. 3PoinTr achieves the best average success rate, demonstrating that all four design choices—3D point tracks, the Perceiver IO encoder, the U-Net cross-attention, and additional human videos—contribute meaningfully to the final performance.
Rollouts
3D Point Track Prediction
Example Policy Rollouts







Results: 3D Point Track Prediction
We also evaluate the quality of 3PoinTr's 3D point track predictions. Here we show Average Distance Error (ADE) and ADE of the 5% of points that move the most (5% ADE) for 3PoinTr and General Flow on real-world tasks (in millimeters). 3PoinTr outperforms General Flow in both metrics on every task, with average error reductions of 28.0% and 44.1% compared to General Flow.